将数据导入Solr时,有很多选择,虽然我们需要通过HTTP与Solr进程通信,但是不一定需要在请求中包含需要索引的文档,所以Solr支持一种remote streaming的方式,可以通过给定一个URL资源,这种情况适用于数据已经在Solr所在机器,或者本地可以访问的文件系统上;还有另外一种方式是使用DataImportHandler (DIH), 该方式可以让Solr从数据库或者其它源上拉取数据,DIH这种方式,伸缩性较强,可以适用于自定义数据源的场景。
Solr支持不同格式的数据索引:
- XML
- JSON
- Java-Bin,该方式需要配合SolrJ进行提交
- CSV
- Rich documents,例如PDF、XLS、DOC、PPT、Text,但是需要通过Solr Cell模块实现。
虽然有很多方法向Solr提交索引数据,但是必须是HTTP POST方式,我们可以在Linux命令行中使用curl发送HTTP POST请求,但是为了跨平台,Solr为我们提供了更好的选择:post.jar,关于它的更多用法,我们可以通过以下命令查看:
$ java –jar post.jar -help
SimplePostTool version 5.0.0
Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]
Supported System Properties and their defaults:
-Dc=<core/collection>
-Durl=<base Solr update URL> (overrides -Dc option if specified)
-Ddata=files|web|args|stdin (default=files)
-Dtype=<content-type> (default=application/xml)
-Dhost=<host> (default: localhost)
-Dport=<port> (default: 8983)
-Dbasicauth=<user:pass> (sets Basic Authentication credentials)
-Dauto=yes|no (default=no)
-Drecursive=yes|no|<depth> (default=0)
-Ddelay=<seconds> (default=0 for files, 10 for web)
-Dfiletypes=<type>[,<type>,...] (default=xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log)
-Dparams="<key>=<value>[&<key>=<value>...]" (values must be URL-encoded)
-Dcommit=yes|no (default=yes)
-Doptimize=yes|no (default=no)
-Dout=yes|no (default=no)
如果我们使用curl进行索引提交的话,我们同样有两种选择:
- curl http://localhost:8983/solr/mycollection/update -H 'Content-type:text/xml; charset=utf-8' --data-binary @data.xml
- curl http://localhost:8983/solr/mycollection/update -F stream.body=@data.xml
第二种是基于form表单的形式提交,通过stream.body参数指定数据,但是需要注意的是solrconfig.xml中模型配置的multipartUploadLimitInKB是2G,如果数据是在Solr所在的机器上,我们可以通过stream.file参数指定,而如果需要从其它URL获取数据,可以通过stream.url给定一个URL参数。
但是无论是stream.file还是stream.url其实都是使用的远程流(remote streaming ),至于要不要开启remote streaming可以在solrconfig.xml中通过enableRemoteStreamingsetting参数设置。
一个合法的XML格式的更新如下:
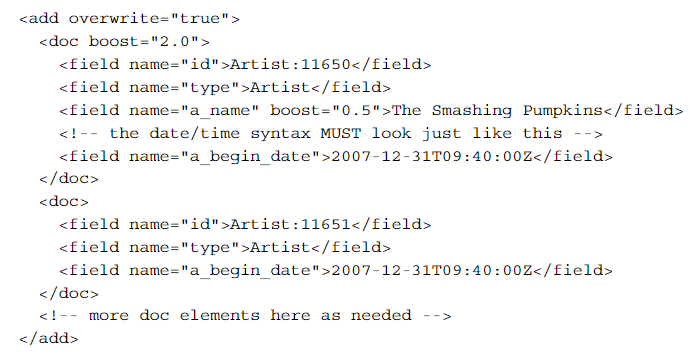
基于XML格式的合法删除:
<!--基于唯一字段值得删除-->
<delete>
<id>Artist:11604</id>
<id>Artist:11603</id>
</delete>
<!--基于query查询结果删除-->
<delete>
<query>timestamp:[* TO NOW-12HOUR]</query>
</delete>
Commit
发送给Solr索引数据并不是立即可检索的,同样对于删除动作也不是立即生效的,这就和数据库一样,所有的变更必须被Commit,Solr中有两种类型的Commit:
- Hard commit,该操作代价比较昂贵,会显著的影响性能,一旦进行Hard commit,则会推送给文件系统进行数据更新,也就是说,变更会被持久化,我们可以在solrconfig.xml中的
<autoCommit>中设置Hard commit相关参数,也可以在请求参数中给出commit=true通知solr进行 Hard commit; - Soft commit,与Hard commit对比,代价相对较小,但是不会被持久化。
关于Solr的Commit我们还需要知道一些重要事项:
- commit操作可能非常的慢,会受到索引大小、硬盘、Solr的预热、缓存状态等影响
- 没有事务隔离,这就意味着当有多个Solr客户端同时修改和commit时,某一个客户端的部分更改会在该客户端还未主动commit的时候就被commit掉了,对于回滚,同样也存在这个问题,所以为了避免该问题,可以考虑使用一个客户端进程负责Solr的更新。
- 避免同时进行多个commit,这与Solr的query预热机制是有关系的,当有一个commit发生,一个新的searcher就会被创建,紧接着就会调用searcher的预热进程(缓存更新等),当预热的searcher越多,意味着内存的开销越大。(为了自我保护,Solr允许在solrconfig.xml中配置maxWarmingSearchers)。
因为以上一些问题的存在,所以使用Solr的时候,需要尽量避免主动commit,对此Solr提供服务端自动commit的配置,我们可以在SolrConfig配置自动Commit的条件(例如文档数量阈值、时间)。
索引优化(Index optimization)
Lucene的索引由一个或多个segments组成,当索引文档的buffer被刷新至硬盘时,将会产生一个新的segment,删除的文档记录在另外一个文件中,在写完一个segment之后,Lucene会将其中一些segment进行合并,一定程度上而言,段数量越多,查询性能就越低;对于索引优化而言,索引越大,消耗的时间则越长。
通常Solr建议在合适的时间显示优化索引,例如在由大量数据加载之后,或者非流量高峰时。
显示的commit和optimize命令有两个boolean可选值:
<optimize waitFlush="true" waitSearcher="true"/>
如果设置成false,则异步处理,即请求立即返回,客户端不阻塞等待commit、optimize正真执行完成。
但是需要注意的是,不管commit或者optimize需要多久,Solr仍会并行的处理search请求,而不是加读锁。
回滚(Rolling back)
Solr中所有未被commit的的更改是可以回滚的,我们可以通过向Solr发送rollback命令:
http://localhost:8983/solr/mycollection/update?rollback=true
当启用了Tansaction log后,Solr则会将原文档写入tlog文件中以达到recovery的目的,Tansaction log主要用于NRT、持久化以及SolrCloud副本的recovery。
启用tlog很简单,只需要在solrconfig.xml中作如下配置:
<updateLog> <str name="dir">${solr.ulog.dir:}</str></updateLog>
文档局部更新(Updating Parts of Documents)
Solr支持3种文档局部更新策略:
- Atomic Updates
- In-Place Updates
- Optimistic Concurrency
Atomic Updates
原子更新允许我们对已有文档做部分更新,而不是整个文档的更新,例如我们只想给文档添加一个新字段值、向已存在值得多值字段(multivalued field)添加新值或者对一个数值字段自增等等。
原子更新只需要我们提供文档变更的部分,并添加特殊的修饰符,如果Solr接受到文档之后并发现这些特殊修饰符,就知道这是对已有文档的原子更新,这就使得Solr支持了NoSQL的特性。
原子更新支持的修饰符如下:
- set
- add
- remove
- removeregex
- inc
另外需要说明的是,原子更新要求schema中文档的所有字段都设置成stored="true"(除去<copyField/>)
下面是一段JSON格式的原子更新DEMO,下面是原索引中的文档:
{"id":"mydoc",
"price":10,
"popularity":42,
"categories":["kids"],
"promo_ids":["a123x"],
"tags":["free_to_try","buy_now","clearance","on_sale"]
}
使用原子更新命令:
{"id":"mydoc",
"price":{"set":99},
"popularity":{"inc":20},
"categories":{"add":["toys","games"]},
"promo_ids":{"remove":"a123x"},
"tags":{"remove":["free_to_try","on_sale"]}
}
更新后的结果:
{"id":"mydoc",
"price":99,
"popularity":62,
"categories":["kids","toys","games"],
"tags":["buy_now","clearance"]
}
In-Place Updates
In-Place Updates原子更新非常相似,从某种意义上说,这是原子更新的一个子集。在常规原子更新中,整个文档在更新期间会被重新索引。但是,在此方法中,只有要更新的字段会受到影响,其余文档不会在内部从新索引。因此,In-Place的效率不受更新的文档的大小(如字段的数量、字段的大小等)的影响。除了这些内部差异之外,原子更新和In-Place Updates之间没有功能差异
当且仅当遇到以下条件时,才会使用该方式进行更新:
- indexed="false"、stored="false"、multiValued="false"、docValues="true"
- _version_字段也是非索引、非存储、单值docvalue字段
- 如果存在copy字段也同样需要是非索引、非存储、单值numeric docvalue字段
鉴于以上条件,所以in-place updates只需要使用到如下修饰符: - set
- inc
Optimistic Concurrency
乐观并发是Solr的一个特性,客户端应用可以使用它来更新/替换文档,以确保其替换/更新的文档未被其他客户端应用同时修改,该特性工作原理是在索引中的所有文档上都需要_version_字段,并将其与更新命令一同指定的_version_进行比对。
通常,使用乐观并发涉及以下工作流:
- 客户端读一个文档,在Solr中可以使用
/gethandler检索文档来保证是否含有最新版本 - 客户端本地修改文档
- 客户端重新提交更改后的文档
- 当提交后的__version__已经与目前最新不一致,则说明版本冲突,该文档已经被其它应用做了更新,则需要重新获取最新文档
如果正在更新的文档不包含_version_字段,并且未使用原子更新,则将通过正常的Solr规则处理该文档;
使用Optimistic Concurrency时,客户端也可以包含可选的versions = true请求参数,要求文档更新后的最新版本包含在响应中,而不需要再次发出冗余/获取请求。
FROM:
- Apache Solr Enterprise Search Server
- Updating Parts of Documents