Tensorflow是一个用来解决数学计算的计算框架,其实不管是CNN、RNN或者是各种变种神经网络模型,本质上都是各种数学公式堆叠在一起的网络结构,Tensorflow的亮点就在于采用数据流图的方式将数学公式粘合在一起,数据流图中的node一般都是各种数学操作,而edge则表示操作结果的数据流向。
Graph
先来看一下下面这段很简单的程序:
x = tf.placeholder(tf.float32, [1, 2], 'x')
y = tf.placeholder(tf.float32, [1], 'y')
w = tf.Variable([[1.], [1.]], dtype=tf.float32, name='w')
bias = tf.constant(1., dtype=tf.float32)
with tf.variable_scope("output"):
out = tf.matmul(x, w) + bias
with tf.variable_scope("loss"):
gap = tf.subtract(out, y)
with tf.Session() as sess:
feed_input = np.array([[1., 1.]], dtype='float32')
expect = np.array([1], dtype='float32')
sess.run(tf.global_variables_initializer())
loss = sess.run([gap], feed_dict={
x:feed_input,
y:expect
})
这段程序的核心就是:f(x)=x*w+bias,然后再计算f(x)与给定y(期望)的差值。
那么对于上面这段tensorflow程序而言,它的Graph是什么样子呢,请看下图:
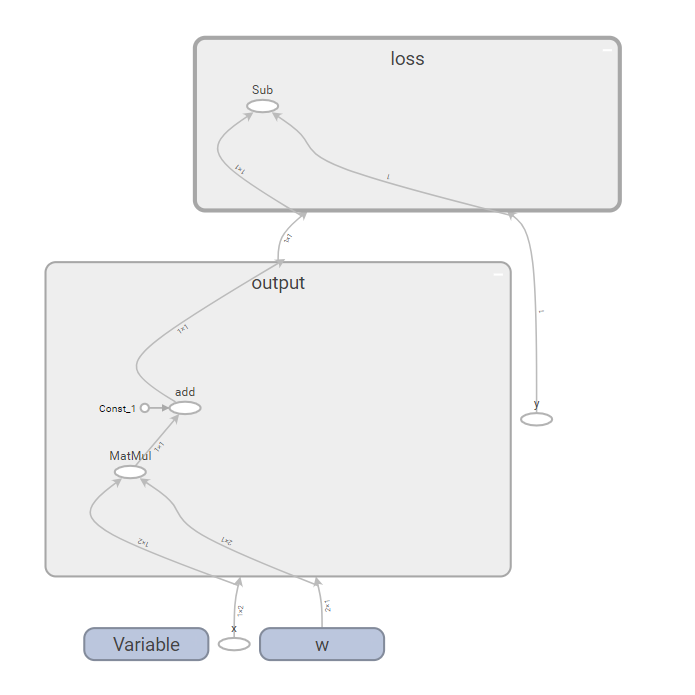
其实这段程序能够简单说明tensorflow中一般神经网络模型的训练原理,只是这段简单程序中没有涉及激活函数和梯度。
OP
数据流图中node其实在tensorflow中叫作op,也就是一个操作(其实也很好理解),op可以是:
- 占位符
- 变量
- 运算操作(加减乘除等等)
无论是占位符、变量、运算操作,本质上都产生了Tensor在图中流动。
对于上图中的椭圆框框,其实就是一个个op,旁边的英文就是该op的name,注意下图中add和sub,其实这两个op的名称准确来说分别为:
- output/add
- loss/sub
为什么为这样,因为op不光有name,还可以通过score进行限定,output和loss分别就是我在程序中为其指定的scope。
什么是模型文件
对于Tensorflow,模型文件就是数据流图(Graph),实际上就是数学操作、之间的依赖关系,以及涉及的参数值,那么Tensorflow中有哪些模型格式呢?
CKPT
ckpt(checkpoint)就是tensorflow模型保存其中的一种格式,也是训练时最常用的,它的好处在于保存断点,可以基于断点再训练。
怎么保存一个ckpt:
saver = tf.train.Saver()
....
saver.save(sess, save_path, global_step)
通常,我们没有特殊指定,ckpt保存下来的的模型主要有三种文件:
.meta保存图结构.index和.data保存图中变量的值
其实一旦开始训练,图的结构就固定了,唯一不确定的就是要学习的参数值,也就是Tensorflow中的Variable,我们不断迭代训练根据loss函数然后求梯度去更新Variable的值,所以采用ckpt保存的话,就会把当前图中各个变量的值保存至.index和.data中。
PB(冻结图)
冻结图是什么呢,顾名思义,就是将Graph中涉及到的Variable参数进行固化,即转变成constant,也就是说一旦一个ckpt转成PB之后,就没法进行再进行参数的更新。所以PB模型可以看做是ckpt的release。
另外PB文件的大小相较于ckpt会小很多,至于为什么会小,你会在下一章节找到答案。
生成PB
下面是一段生成PB模型的代码:
'''CKPT转PB'''
def ckpt2pb(self, checkpoint_dir, output_names=None):
checkpoint = tf.train.get_checkpoint_state(checkpoint_dir)
saver = tf.train.import_meta_graph(checkpoint.model_checkpoint_path + '.meta')
with tf.Session() as sess:
saver.restore(sess, checkpoint.model_checkpoint_path)
if(self.collectGraph):
self.saveNodes(checkpoint_dir, sess.graph)
input_graph_def = sess.graph.as_graph_def()
frozen_graph = convert_variables_to_constants(sess, input_graph_def, output_names)
return frozen_graph
'''保存节点'''
def saveNodes(self, checkpoint_dir, graph):
with open(os.path.join(checkpoint_dir, 'nodes.txt'), 'w') as f:
for node in graph.get_operations():
f.write(str(node.name) + "\n")
'''保存PB'''
def save2pb(self, frozen_graph, saveDir, pbName):
graph_io.write_graph(frozen_graph, saveDir, pbName, as_text=False)
其实上面这段程序的核心是:
convert_variables_to_constants(sess, input_graph_def, output_names)
我们来看一下这个函数对应的几个参数,这里转述一下源码注释(还是怀念Java,算了Python就不吐槽了):
- output_node_names graph中result节点的名称,也就是你需要进行fetch的节点
- variable_names_whitelist 转换成constant的variable节点集合,默认所有variable节点都转换
- variable_names_blacklist 不转换为constant的variable节点集合
这里主要关注一下output_node_names,这个入参取决你在实际场景下,你需要用到什么功能,同时选择哪些输出节点也决定了模型的冗余程度。
在release之后,我们使用模型会关心loss值、会关心accuracy吗?显然不会,我们只会关心infer/predict的结果,更有甚者,比如我们想从一个分类模型中抽取文本向量,那么我们只需要输出层前一隐藏层各个神经元的激活值。
因为Tensorflow中的Graph实际是有向图,所以一旦指定output节点,那么只会保存图中和指定的output节点关联的前向节点,output的后续节点都会在冻结图中丢弃。
Java加载PB
Maven依赖:
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.4.0</version>
</dependency>
这边还是通过使用本文最开始那段程序对应模型为例,然后给出部分相关代码:
/**
* 加载模型
*
* @param model
*/
public Session loadModel(File model) throws IOException {
try {
Graph graph = new Graph();
graph.importGraphDef(Files.readAllBytes(model.toPath()));
return new Session(graph);
} catch (Exception e) {
throw new IOException("模型转Graph失败!", e);
}
}
public float[] infer(Session sess, float[] value, long[] shape) {
if (sess == null) {
throw new RuntimeException("Graph还未加载!");
}
Tensor<Float> input = Tensor.create(shape, FloatBuffer.wrap(value));
Tensor<?> out =
sess.runner().feed("x",input).fetch("output/add").run().get(0);
FloatBuffer buffer = FloatBuffer.allocate((int) out.shape()[0]);
out.writeTo(buffer);
return buffer.array();
}
That's all!