本文翻译至:Segment Merging, Deleted Documents and Why Optimize May Be Bad For You,感兴趣的同学可以直接跳至原文阅读,体验会更好,因为下面有些内容会引起你的高度不适(胡编乱造)。
在详说之前,我们先明确一下,lucene/solr中的已删除文档由两种情况产生,一种就是直接的delete操作,还有就是update操作,因为lucene的索引采用append的方式写,所以在update既需要把之前的文档删除,也需要将新文档写进索引。
段合并和文档删除
lucene/solr的indexing,无论是更新还是删除,都不会立即从索引中移除文档,它是采用一种在原段中“标记为已删除”的方式,使得在search结果中不显示。当然另外一方面,这就导致一定程度的浪费,因为你的索引中可能包含了15%-20%已经删除的文档(实际上已经不需要存在硬盘上)。
在一些情况下,这种浪费可能接近50%,具体的值可以通过numDocs/maxDocs的比值进行确定。
当然,如果这种浪费超过50%的话,是很不明智的,下面就具体来说说。
一个好消息一个坏消息,你想听哪个
好消息就是,保证浪费不超过50%很容易。
坏消息,在solr7.0.1中没有配置用来保证已经删除文档占整个文档比例。
lucene段只"write once"
突然发现外国小哥哥的语言还是挺博大精深的,如果硬生生的翻译成中文,感觉太别扭了,所以对write once干脆不翻译了,相信看完下面内容就知道什么叫write once。
lucene的索引有很多segment组成,一个segment包含了各种文件,如:
- _0.fdt
- _0.fdx
- _9.tim
对于segment,lucene是"write once"策略,当hard commit发生时,当前正在写的segment就会被关闭(即不再写),新的segment会被打开。也就是说,如果一个segment包含10000个doc,一旦segment关闭,就算需要进行标记删除,这个段也还是10000个doc不变。
Merge
上面我们说过,当一个硬提交发生时,segment就会关闭。
而在这个时候,lucene就会检查那个segment可以合并,lucene中有几种段合并策略,但是所有段合并策略都有共同的地方,也就是他们选择将多个segment合并成一个新的segment,被合并的老的segment就会被删除。关键是segment合并完,就不不包含已删除的文档。
打个比方,如果有两个segment,每个segment都有10000个doc,其中2500个标记为删除,当着两个segment合并成一个新segment后,每个segment上已经删除的2500个文档就会在合并过程中清除,也就是新的segment只包含15000个文档。
对于Lucene/Solr中默认的段合并策略TieredMergePolicy(TMP),通常会将已经删除的文档保持在10%-15%。
事实证明,段合并策略在一些情况下,会导致已经删除索引的比例接近50%。
为什么会这样
创建段合并策略时很多因素需要进行衡量,比如:
- 合并任何包含已删除文档的段。 IO负载变得很高,索引性能直线下降。最坏的就是你在删除了0.01%的文档后,就重建整个索引。
- 当有文档删除时,从segment中回收数据。 这个操作基本等价于重写索引,因为索引结构非常复杂,删除一个文档关联的信息代价非常高。
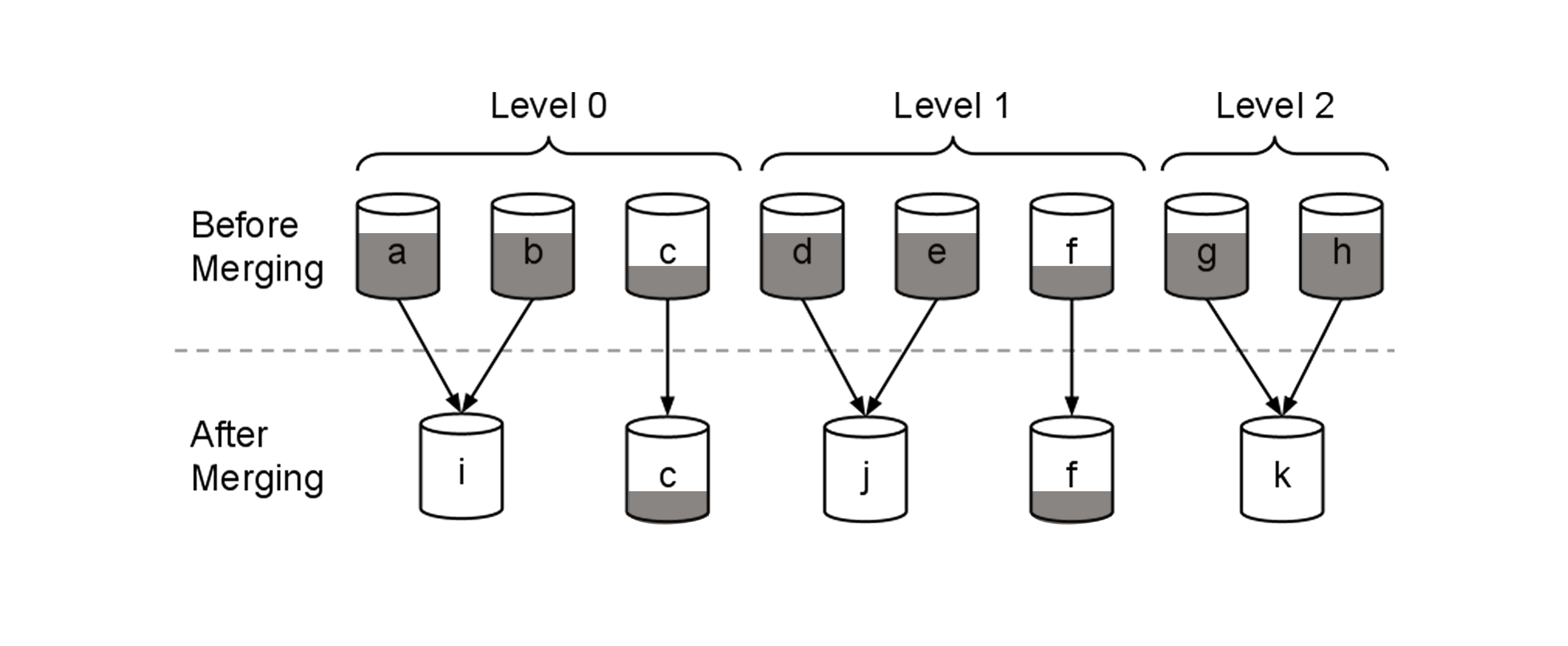
在这幅图中,阴影部分表示已经删除的文档,a、b、d、e、g、h有60%的已删除文档,c和f有20%。
下面我们具体分析一下,已删除文档为什么超过50%,我们先来看看TMP的部分源码:
public class TieredMergePolicy extends MergePolicy {
/** Default noCFSRatio. If a merge's size is >= 10% of
* the index, then we disable compound file for it.
* @see MergePolicy#setNoCFSRatio */
public static final double DEFAULT_NO_CFS_RATIO = 0.1;
private int maxMergeAtOnce = 10;
private long maxMergedSegmentBytes = 5*1024*1024*1024L;
private int maxMergeAtOnceExplicit = 30;
private long floorSegmentBytes = 2*1024*1024L;
private double segsPerTier = 10.0;
private double forceMergeDeletesPctAllowed = 10.0;
private double reclaimDeletesWeight = 2.0;
@Override
public MergeSpecification findMerges(MergeTrigger mergeTrigger, SegmentInfos infos) throws IOException {
//...
}
public MergeSpecification findForcedMerges(SegmentInfos infos, int maxSegmentCount, Map<SegmentCommitInfo,Boolean> segmentsToMerge) throws IOException {
//...
}
@Override
public MergeSpecification findForcedDeletesMerges(SegmentInfos infos) throws IOException {
//...
}
我们发现这里有一个参数maxMergedSegmentBytes默认只是5G,而且从findMerges逻辑中我们也可以发现,存活文档小于maxMergedSegmentBytes的50%时才有资格合并。
假如我们现在有一个包含40个segment的索引,没有segment大小为默认maxMergedSegmentBytes大小,即5g,假设文档的更新时随机更新。在存活文档大于2.5G之前,没有segment可以获得合并的资格。最坏的情况就是所有段中的存活文档都接近了50%,但是还不低于50%,那么这就造成了50%的浪费。
我们能做什么?
看完下面,你会有中分分钟打脸的赶脚。
- optimize/expungeDeletes,其实solr中optimize的本质就是forceMerge,虽然forceMerge会合并会清除掉已经删除文档,但是会产生一个大的段。比如一个100G的索引,maxMergedSegmentBytes依然使用默认值5G,force merge成一个段后,后面在想清理垃圾的话,也就是说存活文档小于2.5G才会触发清理,这就会导致垃圾达到了97.5%
- 调大maxMergedSegmentBytes值,只能说并没有什么卵用。
- 深入了解段合并策略并修改一些底层的参数,其实目前并没有配置选项来改变小于50%触发清理的这个事实。
是不是很绝望,其实呢,solr作为服务已经这么多年了,上面所给出来的,都是边缘案例,所以不要绝望。
其实我们能做的就是不要做上面那些事,尤其是optimize/forceMerge/expungeDeletes,当然也可以让optimize/forceMerge合并成多个段,或者直接修改源码,改变50%这个事实。