随着机器学习算法和技术的进步,越来越多的机器学习应用需要多台机器并行性执行。但是,在集群上进行机器学习的基础设施仍然是不够成熟的。虽然确实存在针对特定用例(例如,参数服务器或超参数搜索)和AI之外的高质量分布式系统的良好解决方案(例如,Hadoop或Spark),但是开发算法的从业者通常从头开始构建他们自己的系统基础结构。
例如,强化学习算法大约有十几行伪代码,Python实现并不需要很多,但是,如果需要在多台机器或集群上有效地运行算法需要更多的工程化工作,实现涉及数千行代码,如定义通信协议,消息序列化和反序列化策略以及各种数据处理策略。
Ray的目标之一是让从业者能够将在个人电脑上运行的算法变为高性能的分布式应用程序,该应用程序可以在集群(或单个多核机器)上高效运行,而且代码行相对较少。这样的框架应该包括手动优化系统的性能优势,而无需用户推理调度,数据传输和机器故障。
那么Ray就是一个用于构建和运行分布式应用程序的快速而简单的框架,套用Ray: A Distributed System for AI中那么多,下面就贴出来Ray: A Distributed Framework for Emerging AI Applications这一论文中对Ray的设计介绍。
编程和计算模型
Ray实现动态图计算模型,它将应用程序建模成在执行时任务的依赖图。在这个模型之上,Ray提供了Actor和一个任务并行编程抽象。这将Ray与CIEL等相关系统区分开来,CIEL只提供任务并行抽象,而Orleans或Akka主要提供了actor抽象。
编程模型
Task
Task表示在无状态的worker上执行的远程函数(remote function),当一个远程函数被调用,用future表示的task结果会被立即返回,future可以通过ray.get()取回结果,也可以作为参数传递给其它远程函数。
下图为Ray的一些API:

Actor
Actor表示一个有状态的计算,每个Actor暴露出来的的方法都可以被远程调用或连续执行。
与Task相似之处在于,Actor的可以被远程执行,也返回future对象。
不同之处在于Actor是在一个有状态的worker上执行。
另外可以将Actor的句柄传递给另外一个Actor或者Task,使其可以方便的调用该Actor上的方法。
下表总结了Task和Actor的一些属性:
| Task(无状态) | Actor(有状态) |
|---|---|
| 细粒度的负载均衡 | 粗粒度负载均衡 |
| 支持本地对象 | 不支持本地对象 |
| 小的更新代价较高 | 小的更新代价较低 |
| 高效的故障处理 | checkpointing代价较高 |
Task通过负载感知调度判断任务粒度,从而做到细粒度调度,每个Task可以在存储输入变量的节点上被调度,并且recovery的代价很低,因此不需要checkpoint或恢复中间状态。
与之相对的是,Actor提供了更高效的细粒度更新,因为这些更新是在内部执行而不是外部,外部状态的更新则需要序列化和反序列化。
举例来说,actor可以用于实现参数服务以及基于GPU的迭代计算,另外,actor还可以用于那些难以序列化的处理。
计算模型
ray采用动态图计算模型,当输入可见时所有远程函数和actor方法被系统自动触发,这个小节,主要介绍如何根据用户程序构建动态图
如果忽略actor不说的话,在计算图中有两种类型的节点:
- 数据对象(data object)
- 远程函数(remote function)或者说是task
有两种类型的边: - 数据边(data edge)
- 控制边(control edge)
Data edge
捕获data object和task之间的依赖关系,确切的说,如果data object D是task T的输出,我们则从T到D添加一个data edge,与之相似的,如果D是T的输入,则从D到T添加一个data edge.
Control edge
捕获嵌套Remote Function产生的依赖关系,如果Task 调用,从 到添加一个control edge。
Actor的方法调用在计算图中也代表一个节点,他们与task一致,但是有一个关键区别,同一个actor上通过后续的方法调用捕获状态依赖,为此,也需要添加一个edge:状态边(stateful edge)。
如果同一个actor上的方法在方法之后调用,则从到添加一个状态边。因此同一个actor上所有方法的调用会形成一个状态链。
下面给出一段用户代码.
代码中@ray.remote修饰了remote function以及actor。调用远程函数或者actor的函数返回future,fucture可以传递给后续的远程函数或者actor方法用来编码任务依赖。每一个actor有一个在它的所有方法中共享的环境对象:self.env。
@ray.remote
def create_policy():
# Initialize the policy randomly.
return policy
@ray.remote(num_gpus=1)
class Simulator(object):
def __init__(self):
# Initialize the environment.
self.env = Environment()
def rollout(self, policy, num_steps):
observations = []
observation = self.env.current_state()
for _ in range(num_steps):
action = policy(observation)
observation = self.env.step(action)
observations.append(observation)
return observations
@ray.remote(num_gpus=2)
def update_policy(policy, *rollouts):
# Update the policy.
return policy
@ray.remote
def train_policy():
# Create a policy.
policy_id = create_policy.remote()
# Create 10 actors.
simulators = [Simulator.remote() for _ in range(10)]
# Do 100 steps of training.
for _ in range(100):
# Perform one rollout on each actor.
rollout_ids = [s.rollout.remote(policy_id)for s in simulators]
# Update the policy with the rollouts.
policy_id =update_policy.remote(policy_id, *rollout_ids)
return ray.get(policy_id)
当调用代码train_policy.remote()后对应的计算图如下:
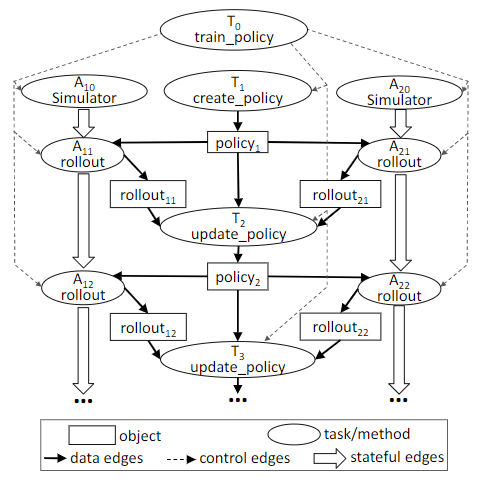
图中只展示了两个actors,每个actor(task标签和)的方法调用都有一个状态边,表示他们共享一个actor的状态。
从train_policy到它调用的task都有控制边。
如果要训练多个策略,那我们可以调用trainpolicy.remote()多次。
系统架构
Ray的架构由应用层和系统层构成,其中应用层实现了API,系统层则提供高可扩展性和伸缩性。如下图:
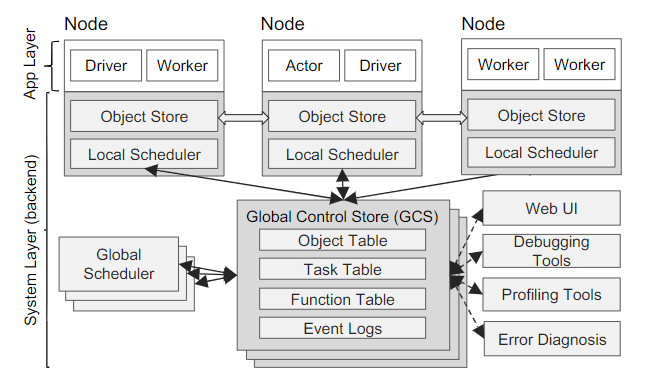
应用层
应用层由三种进程组成:
- Driver:执行用户代码的进程
- Worker:执行driver或者另外一个worker调用的远程函数(remote function或者task)的无状态进程。Worker是由系统层自动启动并分配Task。当一个remote function被声明后,该function会被自动的推送到所有的Worker上,同一个Worker按照顺序执行task。
- Actor:有状态的执行进程。与worker不同的是,actor由worker或者driver显示的实例化。与worker相同的是,Actor也是顺序的执行方法。
系统层
系统层有三个主要的组件构成,所有的组件都具有水平扩展和容错能力。
- 全局控制存储(global control store)
- 分布式调度器(distributed scheduler)
- 分布式对象存储(distributed object store)
全局控制存储(GCS)
全局控制存储(GCS)维持了系统的整个控制状态,这也是Ray设计上的一个独特功能。GCS的核心是一个具有发布订阅(PUB-SUB)功能的key-value的存储。使用分片进行扩展,分片的replication链支撑了其高容错。GCS设计的主要目的是要保持系统的容错能力和低延迟,以至于系统每秒可以动态地产生数百万个任务。
节点发生故障时的容错需要一个解决方案来保存lineage信息,现有解决方案侧重于粗粒度并行,所以可以使用单个节点(例如,master、driver)来存储lineage信息而不影响性能。但是,对于细粒度以及动态工作负载,这种设计是不可伸缩的,因此,需要将lineage storage于其它系统组件分离,这样就可以支持各自独立扩展。
保持低延迟要求最小化任务调度的开销,这包括选择在何处执行,以及随后的任务分派,这涉及到从另外一个节点检索remote输入。许多现有的数据流系统通过将对象位置和大小存储在一个集中的scheduler中来实现这一点,当调度程序不是瓶颈时,这是一种自然的设计。对于像Allreduce这样对分布式训练非常重要的原语来说,在每个对象传输中涉及到调度的代价是非常昂贵的。因此,我们将对象元数据存储在GCS中而不是存储在调度程序中,从而将任务分发与任务调度完全解耦。
总的来说,GCS显著简化了Ray的整体设计,所有的组件通过GCS共享需要的状态,这样使系统中的每个组件自身都变得无状态,这不单单是简化了对容错的支持,也使得可以独立地扩展 Distributed object store以及调度器,通过GCS集中存储,还可以轻松的开发debugging、profileing以及一些可视化工具。
自底向上(bottom-up)的分布式调度
Ray需要每秒动态调度百万个task,每个任务可能只需要几毫秒。我们所知道的集群调度程序都不符合这些要求,大部分的集群计算框架,如Spark、CIEL、以及Dryad都实现了集中式的调度,但是延时都在数十毫秒。例如work stealing、Sparrow以及Canary 能够实现较大规模,但是他们都不考虑数据的本地化,他们或者假设task属于独立的job,或者假设计算图是已知的。
为了满足上述要求,Ray设计了一个两级分层调度程序,它由全局scheduler和每个节点上的本地调度程序组成。为了避免全局调度器过载,在节点上创建的任务首先被提交给节点的本地调度程序。除非节点过载(即,其本地任务队列超过预定义的阈值)或者它不能满足任务的要求(例如,缺少aGPU),否则本地调度程序在本地调度任务。如果本地调度程序决定不调度任务,则将其转发给全局调度程序。由于该调度程序首先尝试在本地调度任务(即,在调度层次结构的叶子中),因此我们将其称为自底向上调度程序。
下图表示了bottom-up分布式调度,Task自底向上被提交,从driver和worker到本地调度程序,如果需要再转到全局调度程序。
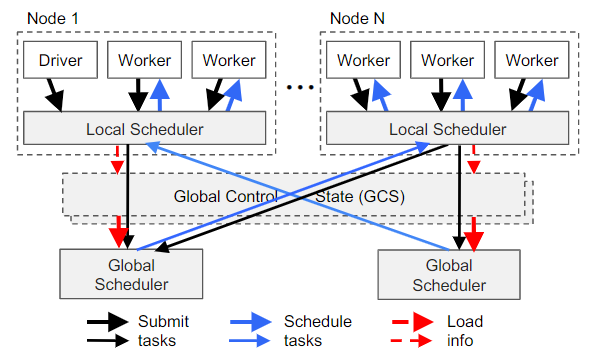
全局调度程序考虑每个节点的load和task的约束来做出调度决策。准确地说,全局调度器能识别满足任务所请求资源足够的节点集合,并且在这些节点中,选择低评估延时的节点。对于某一节点,该时间是目前该节点上在排队任务预估时间以及task的远程输入传输预估时间(即,远程输入的总大小除以平均带宽)的总和。
全局调度程序获取每个节点的队列大小以及节点资源可用性,以及任务的输入位置和来自GCS的空间大小。此外,全局调度程序使用简单的指数平均来计算平均任务执行和平均传输带宽。如果全局调度程序成为瓶颈,我们可以实例化更多副本,所有副本都通过GCS共享相同的信息。这使我们的调度程序体系结构具有高度可伸缩性。
基于内存的分布式对象库(Object Store)
为了最大限度地减少任务延迟,Ray实现了一个内存分布式存储系统来存储每个任务的输入和输出,或无状态计算。在每个节点上,Ray通过共享内存实现了Object Store。这样可以做到运行在相同节点上共享数据的Tasks数据的零拷贝。
如果task的输入不是本地的,则在执行之前将输入复制到本地object store。此外,任务将其输出也会写入本地object store。Replication消除了由于热数据对象导致的潜在瓶颈,并最小化任务执行时间,因为任务只从/向本地内存读取/写入数据。许多AI应用共享一个profile,增加了计算负载的吞吐量。为了保证低延迟,Ray将对象完全保留在内存中,并根据需要使用LRU策略将其驱逐到磁盘。
与现有的集群计算框架(如Spark和Dryad)一样,object store中数据是不可变的。这消除了对复杂一致性协议的需求(因为对象没有更新),并简化了对容错的支持。在节点失败的情况下,Ray通过lineager-execution恢复任何需要的对象。GCS中的lineage stored的跟踪了无状态task以及有状态actor的初始执行,所以我们使用前者来重构库的对象。
简单来说,object store不支持分布式对象,即每个对象都用于单个节点。像大型矩阵或树型结构这样的分布式对象可以在应用程序级实现。
Ray工作流程介绍
下面通过一个简单的例子演示了Ray是如何端到端工作的,这个例子中两个对象a、b相加,它们可以是标量或矩阵。
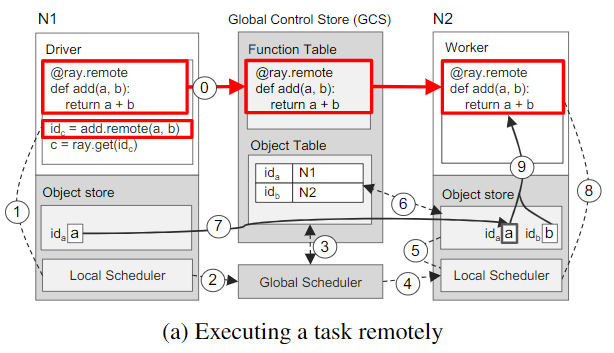
- 步骤0:远程函数
add()在初始化时自动注册到GCS,并分发到系统中的每个Worker - 步骤1:
a和b分别是存储在N1、N2节点上,Driver调用add.remote(a,b)后,先将add(a,b)提交给Local scheduler - 步骤2:Local scheduler将请求转发给Global scheduler
- 步骤3:Global scheduler在GCS中查找add(a,b)参数所在的位置
- 步骤4:Global scheduler决策后,决定在N2上进行Task调度。
- 步骤5:N2节点上的Global scheduler检查本地Object store是否包含
add(a,b)的参数 - 步骤6:检查发现本地Object store中不包含对象
a,则从GCS中查找a的位置。 - 步骤7:N2的object store从N1中复制
a - 步骤8:
add()的所有参数都在存储在本地,Local scheduler则会在本地Worker中调用add() - 步骤9:通过共享内存访问参数
再下面一张图展示了在N2上调度add(a,b)后,N1上执行rat.get()触发的一步步的操作。
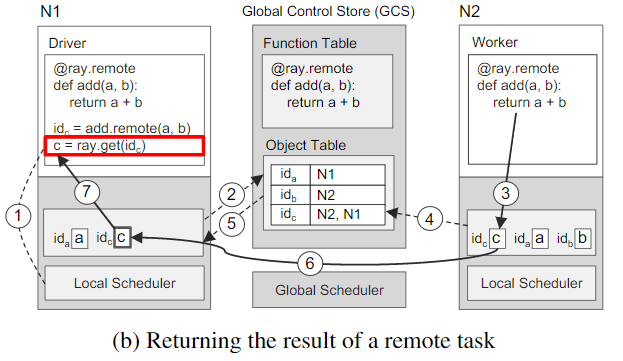
- 步骤1:一旦
ray.get(idc)被调用,使用add()返回的将来的idc检查本地object store,以获取c的值 - 步骤2:因为本地object store没有存储c,则在GCS中查找。此时,因为c还没有被创建,所有没有c的条目,因此,N1的Object Store会在创建c条目时注册一个带有Object Table的回调函数。
- 步骤3:与此同时,N2节点上,
add()完成了执行,在本地object store上存储了结果c - 步骤4:在将
c写入object store时,也会在GCS中添加c的条目 - 步骤5:GCS触发一个将
c条目写入N1的object store的回调。 - 步骤6:接下来,N1从N2上拷贝,最后返回ray.get()的结果。
Ray: A Distributed System for AI
Ray: A Distributed Framework for Emerging AI Applications