IO模型
我们经常讨论的IO模式有以下4种:
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 异步 I/O(asynchronous IO)
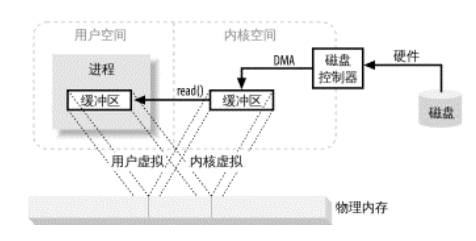
至于怎么会产生这4中IO模式,主要是因为Linux操作系统中分为内核空间和用户空间,所以当read()操作发生时,会经历两个大阶段:
- 等待内核空间准备数据
- 数据从磁盘读入内核空间的缓冲区
阻塞 I/O
阻塞IO会一直阻塞用户进程,这个期间,kernel会一直等待数据准备好,然后将数据拷贝到用户空间,最后kernel返回结果,用户接触阻塞。
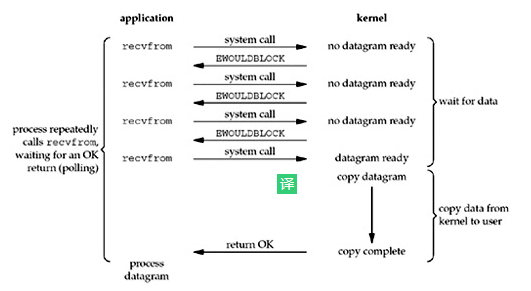
非阻塞 I/O
在内核准备数据阶段,不会阻塞用户进程,用户进程不断的主动询问内核是否将数据准备好,如何没有准备好,则立即返回告知用户进程数据还没准备好。
一旦内核空间准备好数据,并且再次收到了用户的询问,则阻塞等数据拷贝到用户空间并返回。
I/O 多路复用
IO多路复用即使用一个进程同时处理多个IO连接,它的原理是利用select、poll或epoll函数,即单个进程不断轮询所有的连接(套接字、文件描述符),当某个连接上有数据到达了,就通知用户进程。
在该模式中,用户进程调用select(),进程会一直阻塞,直到某个连接进入读就绪状态,select()函数返回。此时用户用户再调用read()方法,这一操作同样阻塞用户进程直到数据从内核拷贝纸用户空间并返回。
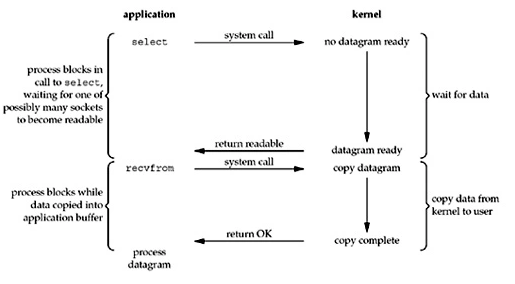
从上图不难发现,IO多路复用和阻塞 I/O模式很像:
- IO多路复用为两次阻塞
- 阻塞IO为一次阻塞
但是IO多路复用的特点就是一个进程同时处理多个连接,所以基于select/epoll的IO多路复用服务优势在处理更多连接上,如果处理连接不是特别多的话,性能比使用多线程(进程)+阻塞IO模型搭建的服务性能要差。
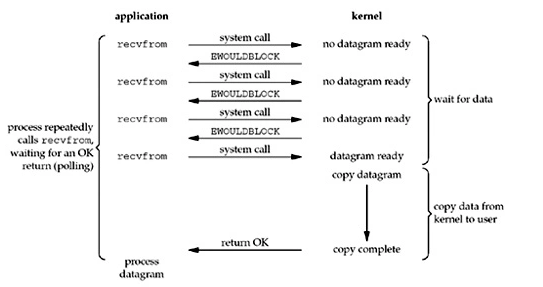
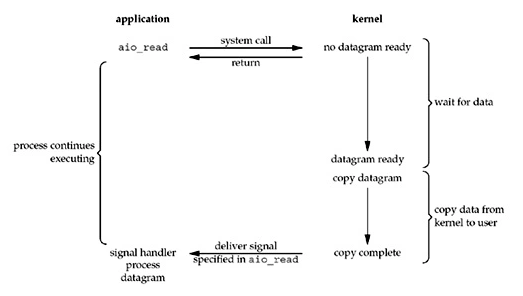
异步 I/O
用户进程发起read()操作后,kernel立即返回,kernel等待数据准备完,然后将数据拷贝到用户内存,然后给用户进程发送一个信号,通知read操作完成了。
TCP服务架构
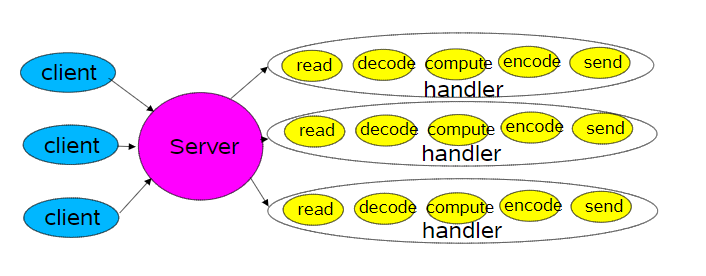
为了处理TCP连接,常用的有两种竞争的架构:
- 基于线程/进程(Thread-Based)
- 基于事件驱动(Event-Driven)
下图是经典的基于线程/进程的设计,每个handler处理一个连接。
Reactor就是基于事件驱动架构处理TCP连接的的最流行的技术实现。这里我们看一个基于单线程的Reactor模型。
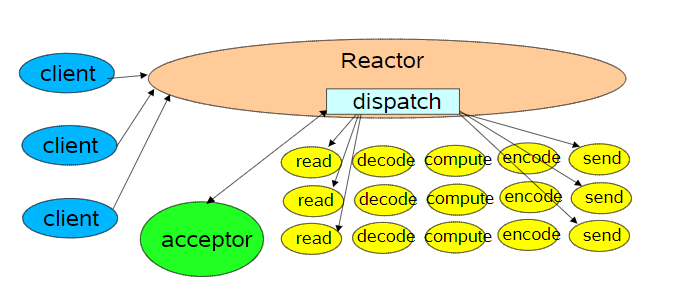
图中的Reactor节点通过调度适当的处理程序来响应IO事件,其核心思想是
- 向 select注册关心的事件(OP_ACCEPT),并为绑定处理实例Acceptor
- Reactor节点调用select()方法阻塞,一直到关心的事件到来
- 遍历所有到来事件,因为最开始拿到的事件都是
OP_ACCEPT,所以由Acceptor.run()处理 - Acceptor为新到来的连接创建Handler
- 因为是新到来的连接,那么服务端的Handler必然先关心,Socket上什么时候有数据可读,所以在Handler再次向select提交对该socket上
OP_READ事件的关心 - 此时又回到reactor节点中,当某个Socket上可读时,调用Handler.run()进行读数据。
- ....
class Reactor implements Runnable {
final Selector selector;
final ServerSocketChannel serverSocket;
Reactor(int port) throws IOException {
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(port));
serverSocket.configureBlocking(false);
SelectionKey sk =serverSocket.register(selector, SelectionKey.OP_ACCEPT);
sk.attach(new Acceptor());
}
public void run() {
// normally in a new Thread
try {
while (!Thread.interrupted()) {
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext())
dispatch((SelectionKey)(it.next());
selected.clear();
}
} catch (IOException ex) {
/* ... */
}
void dispatch(SelectionKey k) {
Runnable r = (Runnable)(k.attachment());
if (r != null)
r.run();
}
class Acceptor implements Runnable {
// inner
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null)
new Handler(selector, c);
}
catch(IOException ex) {
/* ... */
}
}
}
}
final class Handler implements Runnable {
final SocketChannel socket;
final SelectionKey sk;
ByteBuffer input = ByteBuffer.allocate(MAXIN);
ByteBuffer output = ByteBuffer.allocate(MAXOUT);
static final int READING = 0, SENDING = 1;
int state = READING;
Handler(Selector sel, SocketChannel c) throws IOException {
socket = c;
c.configureBlocking(false);// Optionally try first read now
sk = socket.register(sel, 0);
sk.attach(this);
sk.interestOps(SelectionKey.OP_READ);
sel.wakeup();
}
boolean inputIsComplete() {
/* ... */ }
boolean outputIsComplete() {
/* ... */ }
void process() {
/* ... */ }
// class Handler continued
public void run() {
try {
if (state == READING)
read();
else if (state == SENDING)
send();
} catch (IOException ex) {
/* ... */ }
}
void read() throws IOException {
socket.read(input);
if (inputIsComplete()) {
process();
state = SENDING; // Normally also do first write now
sk.interestOps(SelectionKey.OP_WRITE);
}
}
void send() throws IOException {
socket.write(output);
if (outputIsComplete())
sk.cancel();
}
}
该例子中所有Handler都是单线程在执行,只有某一个Socket上有事件到来,Handler才会处理,这中间关键的技术就是select()即IO多路复用。
所以当请求连接较多时,IO多路复用,系统开销会比基于线程的方式小很多。
select、poll、epoll
select
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
select 函数监视分别是writefds、readfds、exceptfds3类文件描述符,用户调用后select函数后,select将需要监控的文件描述符集合拷贝到内核空间,然后遍历需要监控的文件描述符,挨个检查是否有事件到来,如果遍历完没有,那么select会调用让用户进程睡眠,如果一定时间内,某个文件描述符上有事件到来,select还是重新遍历文件描述符,重新收集。
这中间存在几个问题:
- 单个进程能够监视的文件描述符的数量为1024
- 文件描述符需要从用户空间拷贝到内核空间
- 每次都需要重新遍历整个文件描述集合才能够知道哪些文件描述符上有事件到来
poll
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
};
poll的改变主要有两个,一个是文件描述符的结构,还有取消了文件描述符监听上限。但是poll随着监控的socket集合的增加性能线性下降,所以不适合用于大并发场景。
epoll
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll的使用主要分为3步:
- 创建epoll句柄epfd
- 告诉内核你关心哪些文件描述符的什么事件
- 等待epfd上的io事件,最多返回maxevents个事件
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
- LT模式:当epoll_wait检测到文件描述符上事件发生,则将此事件通知应用,应用可以不立即处理。下次调用epoll_wait时,会再次响应应用并通知此事件。
- ET模式:当epoll_wait检测到文件描述符事件发生并,则将此事件通知应用,应用须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
参考: