我们都知道Lucene只能解决文本层面的检索与相似度计算(TFIDF,BM25),无法解决语义层面的检索。尤其在当前机器学习如此火热的情况下,我们已经有很多方式对一个文本转为向量进行语义表征,所以在很多场景下我们会遇到向量检索的问题。
现在的向量检索主要有两大问题:
- 存储
- 检索效率
现在主流的做法是构建一个n x d的矩阵(n为向量特征维度,d为文档数量)存入内存,检索时使用query的向量逐个与nd矩阵中的向量计算相似度,最后取top;当然还有一类采用k紧邻的方式进行向量检索。
而最近看到了一篇paper《Semantic Vector Encoding and Similarity Search Using Fulltext Search Engines》这里面给出了一个利用全文检索引擎解决语义向量检索的问题,个人感觉很多细节没有说清楚,尤其索引和收集评分相关的细节,暂且说一下大致的思想吧,后面继续跟进。
该论文的主要思想,就是将语义向量编码为文本特征,这样就可以被lucene进行索引,然后在用lucene进行搜索。
##语义向量编码为文本特征
向量编码为文本特征的主要方法为:(1)特征标识+精度编码+特征值 (2)特征标识+区间编码+特征值
- 特征标识:如特征序号,如0、1
- 精度编码标识:P2表示精度为2,如果要保留3位小数,则为P3
- 区间编码:按照特定步长,将特征值编码至特定区间,具体我们在下面细说。
- 特征值:如0.12特征值表示为i0d12,-0.2表示为ineg0d2,其中neg则表示负数
特征标识+精度编码+特征值
在特征表示的时候,会有精度标识,那么则会存在四舍五入,如果我们统一采用精度为2编码,对于向量:则可以编码为:
特征标识+区间编码+特征值
这里比较有意思的就是区间编码,我觉得这也是该论文一个核心的地方,因为特征值比较接近的都应该或落在一个区间内,这也是为什么能够将语义向量转为文本编码,然后使用全文检索引擎搜索的原因。
假如我们步长设置为0.1,那么对于特征值0.12,应该会落入[0.1,0.2]这个区间,使用下区间的值作为该特征值即为0.1;同样步长设置,再举一个例子,特征值-0.13,应该会落入[-0.2,-0.1],使用下区间的值作为该特征值即为-0.2。
同样对于,步长设为0.2,可以编码为:,对应文本特征表示为:其中I5是步长0.2的符号表示,可以看作是1/5。
上面的按步长进行区间编码,实际上是让向量变得更加稀疏,个人理解能够这么做,应该先交代一个背景,我们计算向量相似度较常用的就是余弦相似度,为了减少计算相似度时的开销,在索引前这些向量都应该做了标准化,即转为单位向量,这样计算相似度时只需要做点积,在点积时,越是趋于0的值对相似度贡献越小。
基于特征值越是趋于0,对相似度贡献越小这个思想,该paper提出了一个名字很NB的技术:高通滤波技术(High-Pass Filtering Techniques )。
对精度编码和区间编码结果进行合并作为向量的文本特征。
高通滤波技术
高通滤波技术,核心思想就是我们上面背景补充中说的,丢弃特征贡献小的值。
修剪
设置阈值,丢弃绝对值低于阈值的特征值,如阈值为0.1,那么w则会丢弃0.0.65这个特征。
最优值
对向量的每个特征按照绝对值排序,并且只将排序靠前的一些特征保留。如果将这个值设为1,那么向量w=[0.12, -0.13, 0.065]中只有-0.13会被考虑。
看上去就这么两个简单的概念,用了这么骚包的一个名字。
对比与主流向量搜索的开销
说实话这一篇幅我没太能看懂,很多细节没有说清楚,我只能基于我那边全文搜索经验给出一点说明。
传统简单粗暴的搜索
在索引阶段,在内存中保存所有文档的向量,假如有d个文档,每个文档向量维度为n,则在内存中存储一个n x d的一个矩阵。
在搜索阶段,假如我们使用余弦相似度,我们需要使用query的向量与d个文档的向量点乘积(已经归一化),时间复杂度大致为O(nd),最后取分值最高的k个文档。
基于编码
最坏的情况,我们每个个向量每个维度存储一个token,那么空间复杂度为O(nd)。
真心没太懂,前面说到了编码有两种:(1)基于精度和(2)基于区间,那最坏不应该是O(nd)吗?
而对于每一个query向量,也都编码成文本特征,对于每个文本特征检索出对应的文档集合,以及中每个文档中的词频(term frequency ),然后使用点积计算得分,加入候选文档中,最后取出top k。
这里跳跃性太大了,为什么是文档中的词频,词频拿来干嘛,前面文本编码时,不是已经加了特征唯一标识了吗,词频不都应该是1吗?
原文:Each dimension of the query vector q contains a string-encoded feature . For each we fetch a list of documents together with term frequency tn in that document: tf(;).For each of these (;tf(;)) pairs we add the corresponding score value to the score of document in a list of result-candidate documents. The score computation contains a vector dot-product operation in the dimension of the size v of feature vocabulary V that can be computed in O(v). Document is added to the set C of all result-candidate documents, which we sort in O(clogc)time and return the top k results
采用高通过滤技术
前面说到,采用编码的方式空间复杂度为O(nd),那么采用高通滤波技术,只保留top m个重要特征,那空间复杂度就是O(md),其中m<=n。
因为保留了重要特征,所以空间复杂度和时间复杂度都会下降,检索方式和采用编码的检索方式差别不大。
贴出论文给出的复杂度数据:
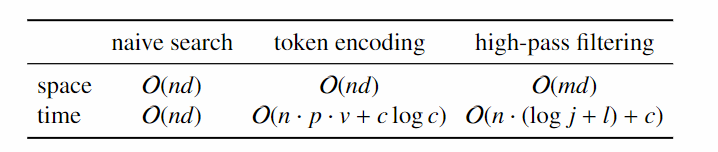
参数说明:
- :语义向量特征的维度
- :文档个数
- : 裁剪后向量维度
- : 倒排链的长度
- : 每个维度上值的个数,即该维度上词典大小
- : 候选集大小
- : 去重后特征值的数量
- : 索引中一个特征值对应的文档数量
Semantic Vector Encoding and Similarity Search Using Fulltext Search Engines