如果你的索引量太小,不要折腾这些东西,个人觉得真心没必要,因为没有效果,不如把时间花在其他技术上。
searcher预热
很多人看到searcher预热可能会觉得,这和缓存有什么关系,我们看一下这张简单的图:
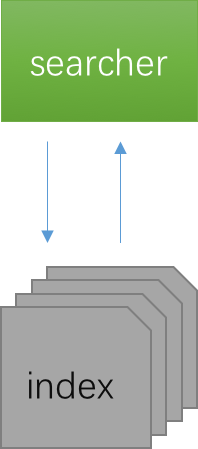
这是一个搜索最简单的图,但是这张图也说明了搜索的本质:读文件,因为index就是一个个文件,那么我则需要在这张图中加一点东西:
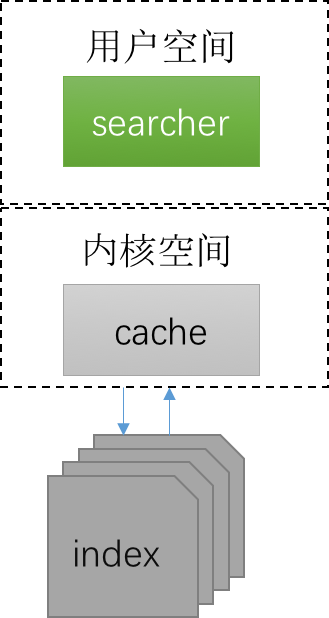
实际上我们读index文件是托管给内核的,对于经常读的内容,操作系统系统实际上是帮我们cache住了,这也是为什么我们去linux系统上看memory的时候,实际上就部署了一个java服务,但可能内存没了,再看看cache/buffer(这变不扩展说buffer)占据了很大一部分。
所以searcher预热在索引服务起来或者searcher切换后很有必要,这也是我将它归到缓存中的原因。
但是开启searcher预热我们还得关注一些东西,那就是你索引预热的耗时和频率,如果你的searcher预热需要消耗太长时间,而且你的索引又频繁更新,那么这也会是一个灾难。
窗口大小
通常我们百度/google,只会翻前两页,反正我没有翻过第二页,甚至连第二页都翻的很少,所以这样的用户习惯就给了我们发挥的空间。
假设我们前台一页展示30条,某一次query命中了100000结果,那么翻第一页我们需要计算出top30,但此时我们完全可以计算top60,并缓存结果,因为计算top30和top60的代价基本没有什么差别,而且用户在翻下一页时完全可以从缓存中get。而如果我们不缓存,相当于又要再计算一次top60。
filter缓存
了解搜索的人都知道filter和query最大的区别就是:query会计算得分,filter不计算得分,所以理论上filter的效率要比query的效率高,所以我们要善用filter。而对于query + filter这种查询情况,也会减少文档score的数量,我们可以简单看作是只对两个集合交集进行score。
我们简单看一下lucene4.7.x中Filter类:
public abstract class Filter {
public abstract DocIdSet getDocIdSet(AtomicReaderContext context, Bits acceptDocs) throws IOException;
}
也就是说Filter实际上需要我们返回DocIdSet对象,DocIdSet是什么呢:
public abstract class DocIdSet {
/** Provides a {@link DocIdSetIterator} to access the set.
* This implementation can return <code>null</code> if there
* are no docs that match. */
public abstract DocIdSetIterator iterator() throws IOException;
public Bits bits() throws IOException {
return null;
}
public boolean isCacheable() {
return false;
}
}
这里最关键的一个方法就是public Bits bits() throws IOException,Bits的实现由那些呢,常用的有下面两个:
- DocIdBitSet
- FixedBitSet
但其实都可以看做是BitSet,不了解的可以自行查阅,采用Bitset存储文档doc,将会大大压缩空间大小,假设索引中最大文档id为1000000,如果我们用数组存储20w个doc,那么大小大概是4byte*200000=781kb,那如果用BitSet存储的话,那么大小恒定为1000000 /64 * 8byte= 125kb,何乐而不为呢,这样的话我们可以Filter对应的DocIdSet对象进行缓存。
doc缓存
doc缓存就是对查询结果进行缓存,其实本人是不太喜欢doc缓存,通常来说,doc缓存的命中率实在是太低了,有点吃力不讨好的感觉,但是如果你满足下面的要求的话,还是可以考虑doc缓存的:
- 索引更新频率低
- 查询场景符合28原则
索引频率低的话,就意味这缓存不会频繁失效,如果频繁失效那将会是一个灾难,在内存空间中,缓存一般存在于年老代,对于并行GC来说,只有一次年老带才会收集,所以无意义的缓存,非但不会提升效率,还会增加full gc的频率。
查询场景符合28原则,就意味这大部分查询集中在某些词上,也就是所谓的热词,这样的话缓存就会很有意义,缓存的命中率会很高。
如果你符合上面两种场景,那么你还要考虑缓存的策略,Lucene已经内置了两种换粗策略: - LRU (Least recently used)
- LFU (Least Frequently Used)
不多说,看着选择,毕竟内存不是无限的,尽量缓存有效信息。
另外,你可以考虑缓存的自热热略,因为切换Searcher是必然存在的,那么就可以利用旧Searcher的缓存来预热新searcher中换粗。
小对象缓存
这个在Solr中并未有相关说法,但是如果你有搜索的长期线上调优经验的话,就会发现GC对搜索性能不小,所以我们需要做得就是尽量降低GC频率,如果降低GC频率呢,其中一个办法就是尽量少产生临时对象,如果scoredoc对象,一次collector产生的数量数以万计,这种对象实际是可以采用对象池去管理的。
额外说一点关于GC策略的调整,如果你的服务器已经接近满负载在跑,那么你就不要想着通过GC策略缩短搜索的响应时间,反而会是一个灾难。
That's all!